Deploying Batch Scale Software
Overview
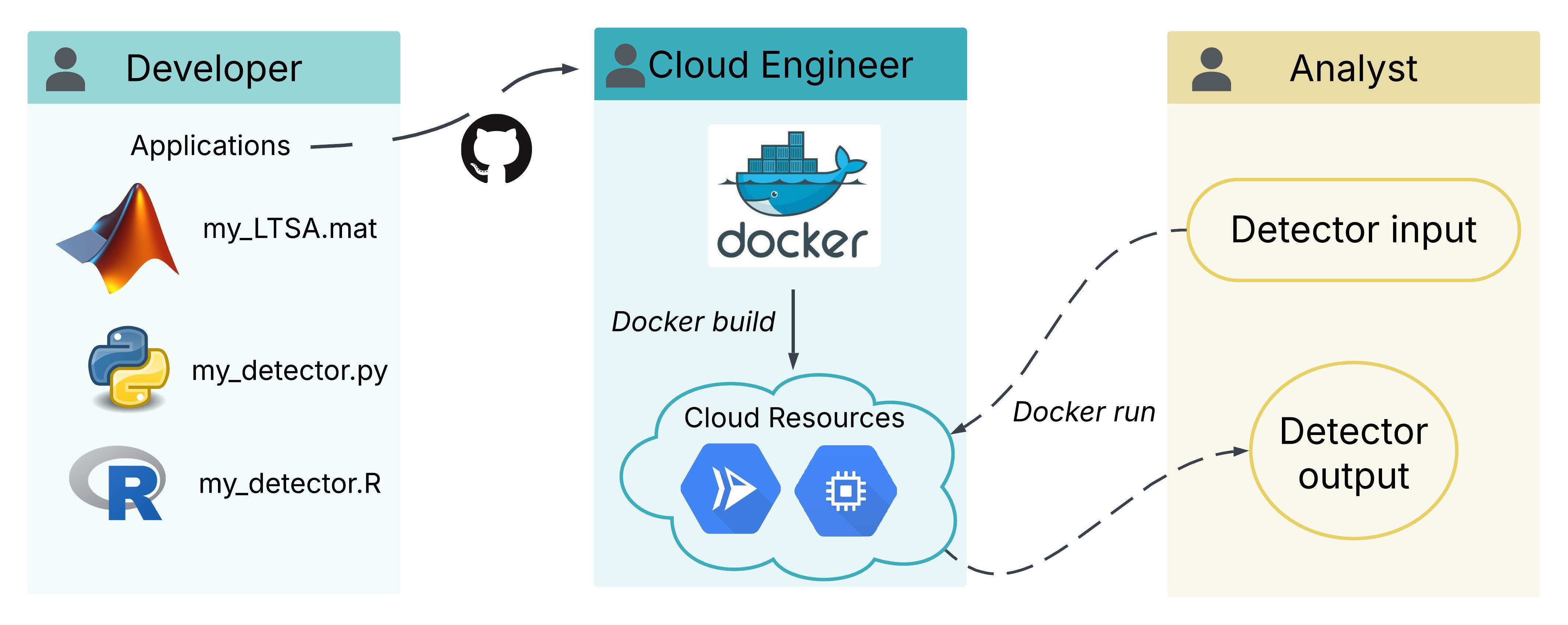
Cloud-based batch processing enables hyperscaling of acoustic data analysis, allowing any number of datasets to be processed simultaneously by multiple analysts. This batch framework will save the NOAA passive acoustic community valuable time, leading to more efficient generation of acoustic data products to support conservation and management.
Cloud processing resources are available through the Google Cloud Composer environment, which provides a user interface to set software parameters, trigger processing jobs, and track progress. Users interact with these processing tasks through DAGs (Directed Acyclic Graphs), which each represent a workflow. If you receive a permissions error when trying to access Cloud Composer or the processing-associated storage buckets, please submit this form so the cloud admins can provide the necessary permissions. To maintain data security, all software outputs will be stored in a default cloud output bucket specific to that software. Users will then move their output to their preferred cloud storage location either using drag and drop methods on the pam-ww or using gsutil commands following these instructions. Current software available in Cloud Composer includes:
- LFDCS multi-species baleen whale detector (2kHz and 120 Hz detectors)
- PyPAM Soundscape Metric generation (PyPAM based Processing - PBP)
- Minke and Humpback Whale detectors
- Multi-species Whale Model
While there are unique steps and instructions for each software in Cloud Composer, the general workflow consists of:
- Navigate to the appropriate DAG in Cloud Composer
- Enter the required metadata to configure the software
- Click “Trigger”
- Confirm the processing job was completed correctly and review outputs
- Move outputs from the default output bucket to the user preferred cloud storage location
Software specific instructions
PyPAM:
- PyPAM protocol
- Input bucket for YAMLS (pypam-prod-yamls)
- Output bucket for Soundscape metrics (pypam-prod-outputs)
- PyPAM Technical Cloud Documentation
LFDCS:
Minke/Humpback:
Whale Model
- Documentation (forthcoming)
- Whale-classifier-output-prod